SDXL with Automatic1111
Automatic1111 can now generate SDXL images admirably. Here are the models you need to download, extensions that would dramatically increase your productivity, and a few recommended settings that will make your life easier.
The settings and extensions listed on this page is what I personally use when I generate SDXL images with Automatic1111.
I will update this page when I have more experience with SDXL. Please feel free to send me a message on social media if you’d like to share your feedback or ask questions. Contact me.
Models
You can download the models into the folders defined by the different user interfaces, but I would recommend that you have a centralized location to store all the models. This way, you would save a lot of space on your hard disk or SSD.
I store my models inside ~/sd/models, with additional subfolders for the different types of models.
Checkpoints, VAE, LoRA
Direct download links via HuggingFace:
Or download with wget:
# SDXL 1.0 Base
cd ~/sd/models/checkpoints
wget https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
# SDXL 1.0 Refiner
cd ~/sd/models/checkpoints
wget https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
# Fixed 0.9 VAE
cd ~/sd/models/VAE
wget https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/resolve/main/sdxl_vae.safetensors
# SDXL Offset Noise LoRA
cd ~/sd/models/Lora
wget https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_offset_example-lora_1.0.safetensors
Upscalers
These are not strictly necessary for the SDXL workflow, but they are the best upscalers to use with SDXL, so I would recommend that you download them. They can be used with SD 1.5 generations also.
Direct download links via HuggingFace:
Or download with wget:
# 4x_NMKD-Siax_200k upscaler
cd ~/sd/models/models/ESRGAN
wget https://huggingface.co/uwg/upscaler/resolve/main/ESRGAN/4x_NMKD-Siax_200k.pth
# 4x-UltraSharp upscaler
cd ~/sd/models/models/ESRGAN
wget https://huggingface.co/uwg/upscaler/resolve/main/ESRGAN/4x-UltraSharp.pth
Config
So that Automatic1111 knows where to load your models, edit the webui-user.sh for additional folders to look for models
Example settings for M1/M2 setup. You should substitute your own settings.
export COMMANDLINE_ARGS="
--no-half
--api
--skip-torch-cuda-test
--ckpt-dir ~/sd/models/checkpoints
--embeddings-dir ~/sd/models/embeddings
--hypernetwork-dir ~/sd/models/hypernetworks
--lora-dir ~/sd/models/Lora
--esrgan-models-path ~/sd/models/ESRGAN
--vae-dir ~/sd/models/VAE
"
Extensions
You don’t need to use the following extensions to work with SDXL inside A1111, but it would drastically improve usability of working with SDXL inside A1111, and it’s highly recommended.
- You can install these extensions on the Extensions UI panel.
- I tend to install my extensions by running
git clonein the folder directly, simply because it is faster.- I often have to install multiple extensions on a fresh GPU instance, and doing it this way instead of going through the GUI means that I could run it in a script, or just paste into the terminal.
- Restart the Web UI process for them to load.
- Some extensions will download additional models from the Internet. This is normal.
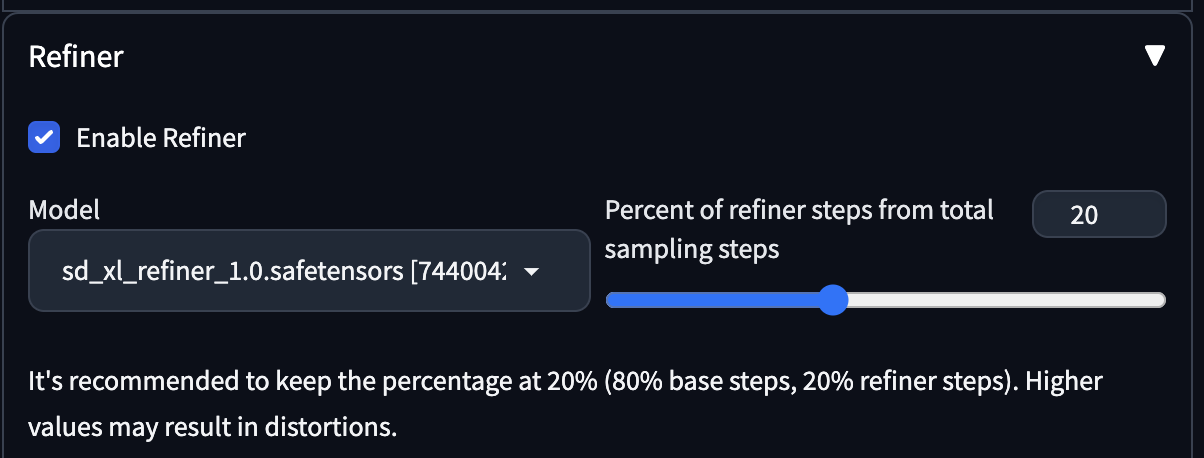
Refiner
This allows you to run refiner on the txt2img page and not have to use img2img, which would be the official workflow.
https://github.com/wcde/sd-webui-refiner
Extension loads from refiner checkpoint only UNET and replaces base UNET with it at last steps of generation.
If you use the GUI:
https://github.com/wcde/sd-webui-refiner
Or download with wget:
# Refiner
cd ~/sd/stable-diffusion-webui/extensions
git clone https://github.com/wcde/sd-webui-refiner.git
Screenshot:
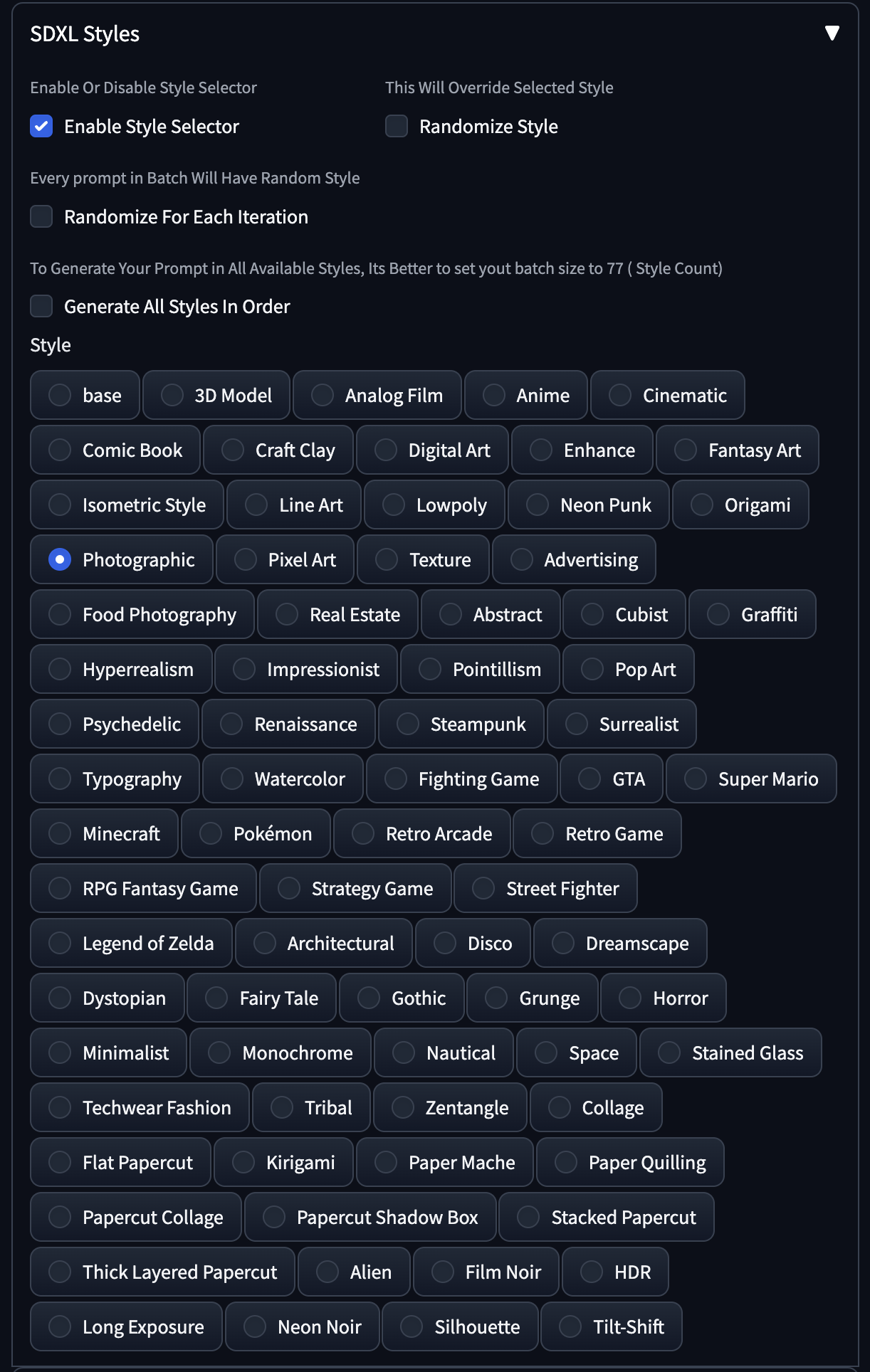
SDXL Style Selector
SDXL uses natural language for its prompts, and sometimes it may be hard to depend on a single keyword to get the correct style. The style selector inserts styles to the prompt upon generation, and allows you to switch styles on the fly even thought your text prompt only describe the scene.
https://github.com/ahgsql/StyleSelectorXL
This repository contains a Automatic1111 Extension allows users to select and apply different styles to their inputs using SDXL 1.0.
If you use the GUI:
https://github.com/ahgsql/StyleSelectorXL
Or download with wget
# SDXL Style Selector
cd ~/sd/stable-diffusion-webui/extensions
git clone https://github.com/ahgsql/StyleSelectorXL.git
Screenshot:
Settings
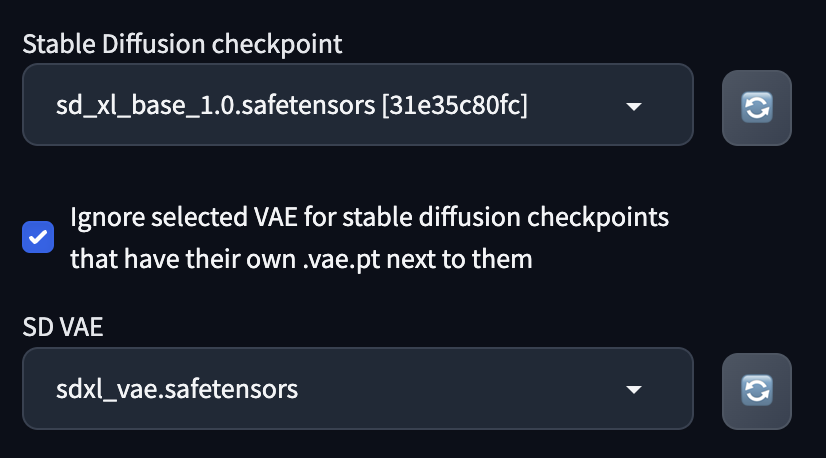
VAE
You should add the following changes to your settings so that you can switch to the different VAE models easily. For SDXL you have to select the SDXL-specific VAE model. This UI is useful anyway when you want to switch between different VAE models.
- Settings > User Interface > Quicksettings list
Type vae and select
sd_vae_as_defaultsd_vae
After restarting the Web UI, you will see these additional settings at the top of your screen.
Here’s what it normally looks like one a wide screen:

Workflow
The SDXL flow is a combination of the following:
- Select the base model to generate your images using
txt2img- The SDXL default model give exceptional results
- There are additional models available from Civitai.
- Select the SDXL VAE with the VAE selector.
- Enter your text prompt, which is in natural language
- Don’t write as text tokens.
- Write them as paragraphs of text.
- Enter your negative prompt as comma-separated values.
- Similar to how you write them right now for SD 1.5 models.
- Optionally, use the refiner model to refine the image generated by the base model to get a better image with more detail.
- In the official workflow, you would use the img2img for this.
- With the Refiner extension mentioned above, you can simply enable the refiner checkbox on the txt2img page and it would run the refiner model for you automatically after the base model generates the image.
- As recommended by the extension, you can decide the level of refinement you would apply.
- 20% is the recommended setting.
Notes
- Resolution: 1024x1024
- SDXL is trained with 1024x1024 images.
- Generating at 512x512 will be faster but will give you worse results.
- You should either use exactly 1024x1024 res or multiples of it.
- 1024x1024 gives the best results.
- Multiples fo 1024x1024 will create some artifacts, but you can fix them with inpainting.
- Inpaint with Stable Diffusion
- More quickly, with Photoshop AI Generative Fills.
- SDXL-specific LoRAs
- SDXL requires SDXL-specific LoRAs, and you can’t use LoRAs for SD 1.5 models.
- Natural langauge prompts
- SDXL uses natural language prompts.
- You can type in text tokens but it won’t work as well.
- Favors text at the beginning of the prompt
- SDXL places very heavy emphasis at the beginning of the prompt, so put your main keywords in the front.
- The degree of this emphasis is much more significant than the SD 1.5 models
- ADetailer / Face Editor.
- Not really necessary.
- You can use them, but I have gotten strange results when using with SDXL generations.
- Test it yourself and decide.
- Highly image dependent.
- Hires fix.
- You can us it, but I have gotten mixed results.
- The results are not necessarily that much better.
- It does use a lot of processing time because your images are now at least 1024x1024.
- I believe that you can’t just use any upscaler.
- I recommend using
4x_NMKD-Siax_200kif you plan on using hires fix.